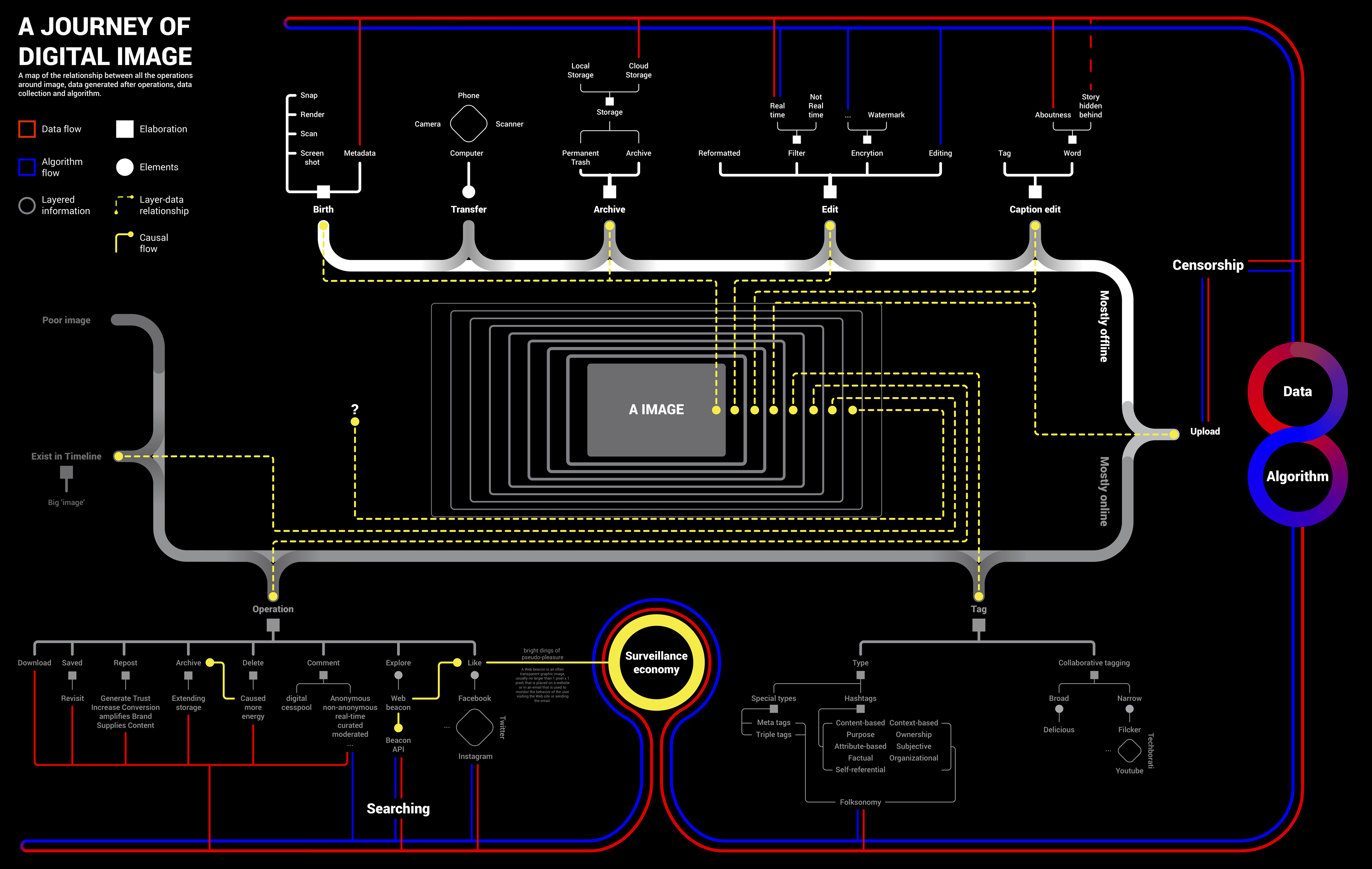
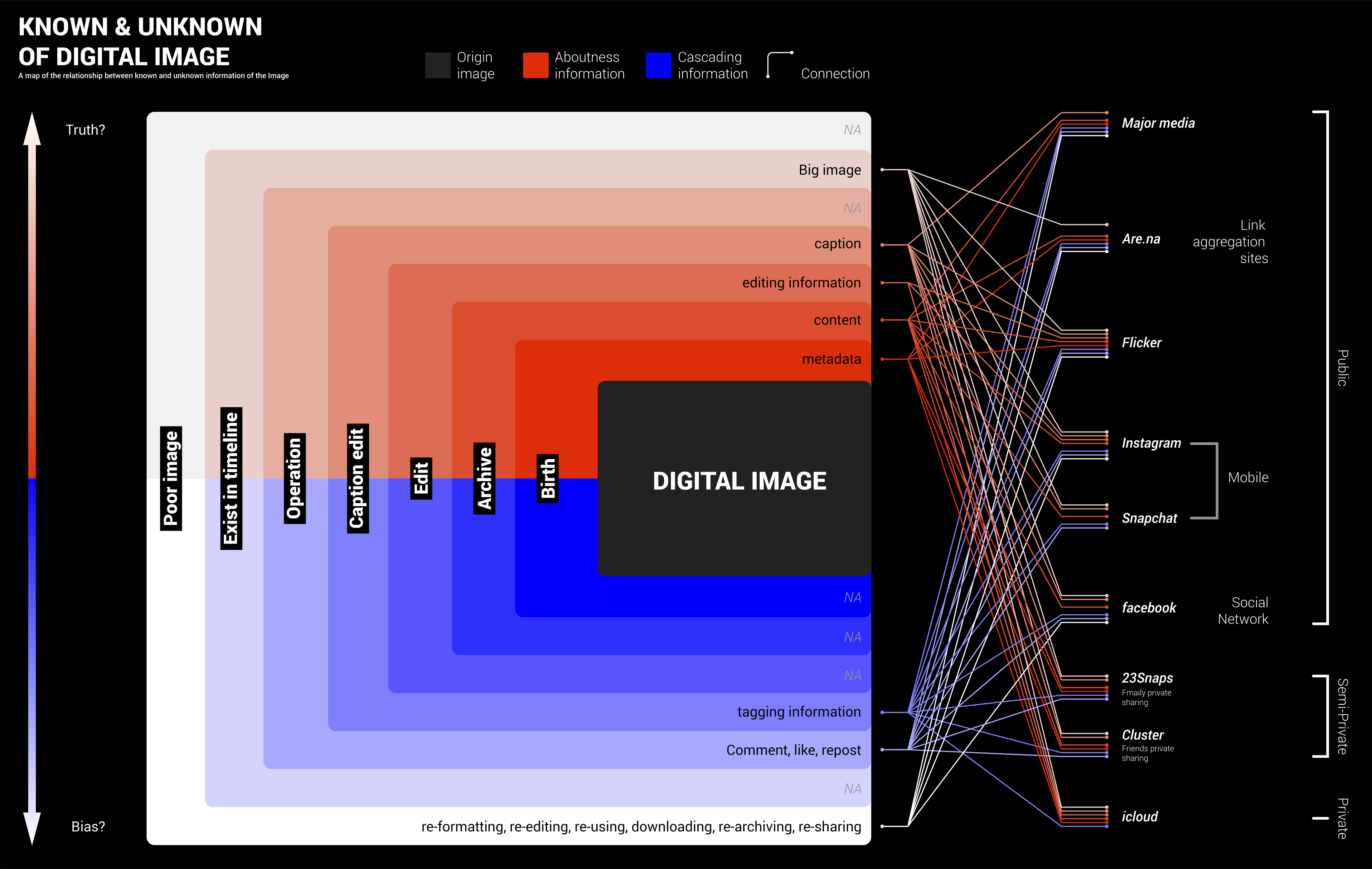
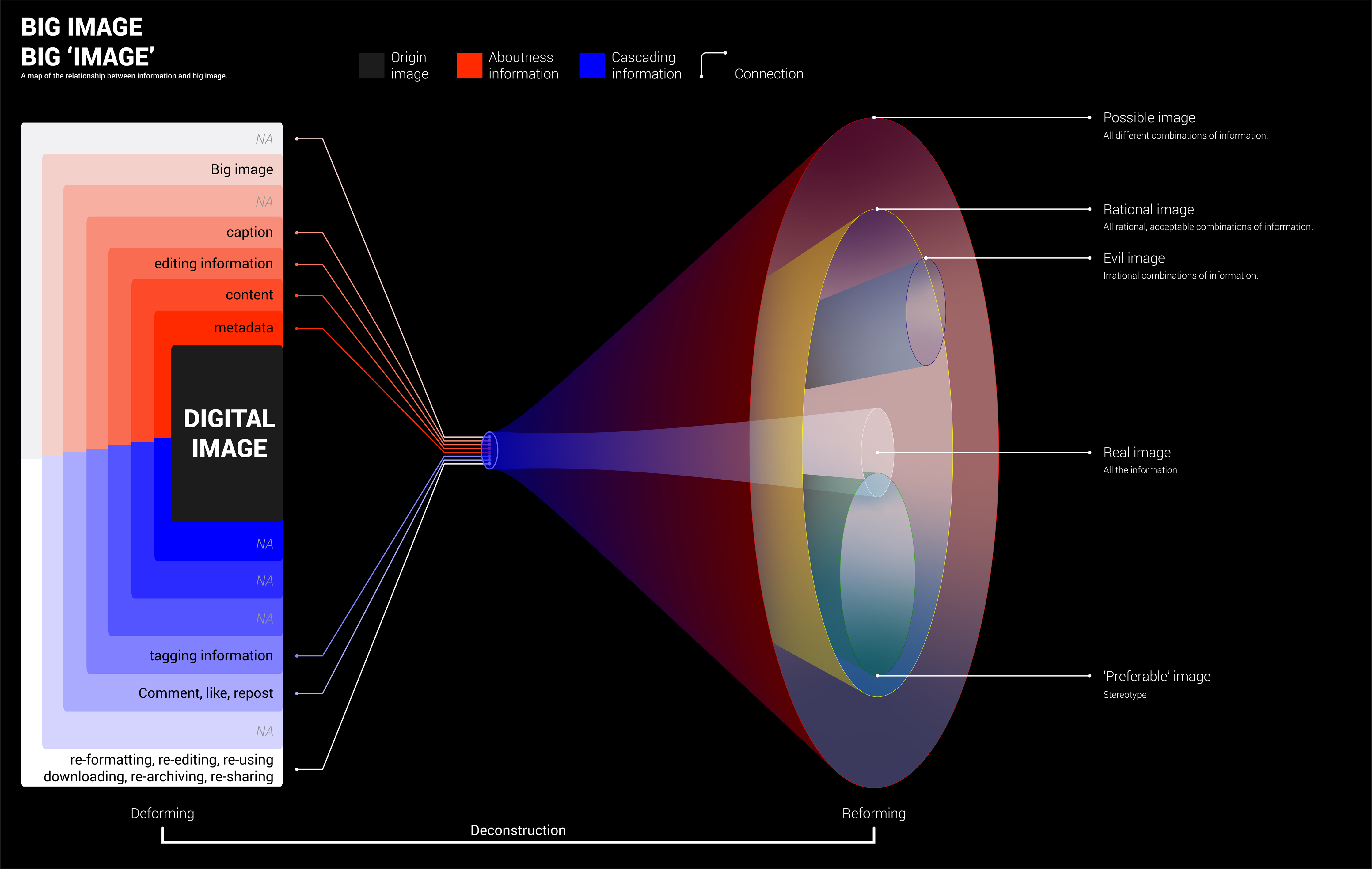
Digital profiling is the process of gathering and analyzing information that exists online about an individual. Platforms who provide services always have control of this powerful tool. As a result, I used Twitter API as the principle medium to conduct 'digital profiling' as a third party. The visual identity of the new digital profile is not an ads interest list anymore, but a graph that stores personal information that could be used as an avatar. On top of the new visual identity, I speculated several possible applications of the new visual outcome. The idea put forward in this thesis is that shifting the purpose of digital profiling toward being human-centered rather than advertising-driven may draw worthwhile arguments about the practicality and policy issues. My point is to demonstrate my future vision or wish for this technology and propose a mutually beneficial strategy for tech companies.
mimesis is a thesis project initiated and developed by Yangyang Ding. Yangyang is a master’s degree candidate in Industrial Design at RISD. His thesis advisory committee consists of
Agatha Haines,
Minkyoung Kim, and
Nic Schumann. Also special thanks to
Paolo Cardini,
Benjamin Jurgensen, and
Benjamin Vu.
mimesis1.0
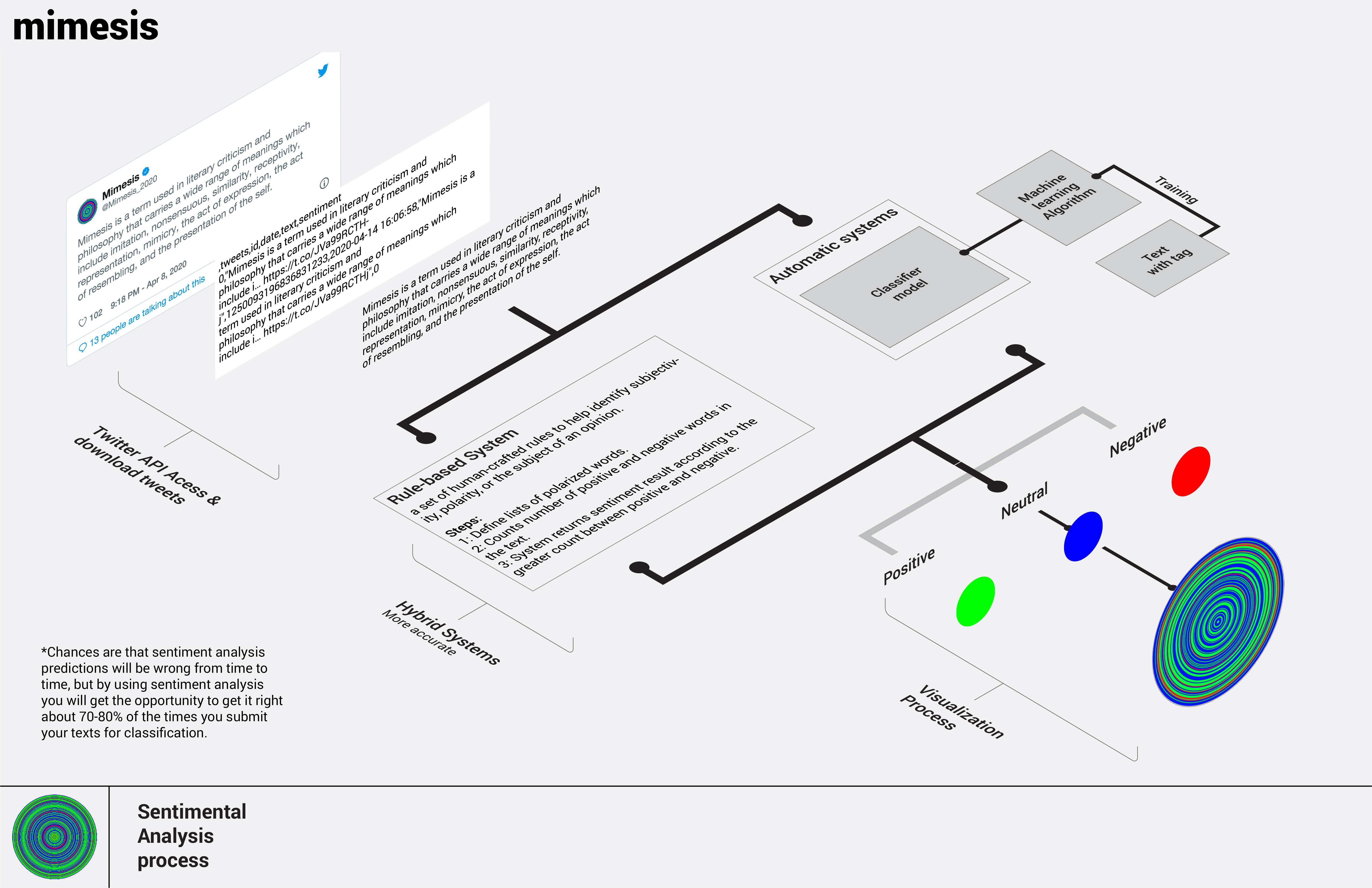
Twitter is the central platform involved in the process. Twitter API has three aggregated streams of Tweets, which are home timeline, user timeline, and mention timeline. The home time- line consists of retweets and the user's tweets, which represent the user's thoughts. Mimesis1.0 pulls tweets from the Gigi Hadid home timeline and then pipes tweets into a sentiment analysis model which will spit out 1,0,-1 as sentimental results meaning positive, neutral and negative. After that, it uses Processing to match these digits to green, red and blue and draws circles from inside to the outside. As a tree ring storing climate and atmospheric conditions data, Mime- sis1.0 stores personal sentiment data. It is a visual representation of the internet user. It is an avatar, as well as simulacra.

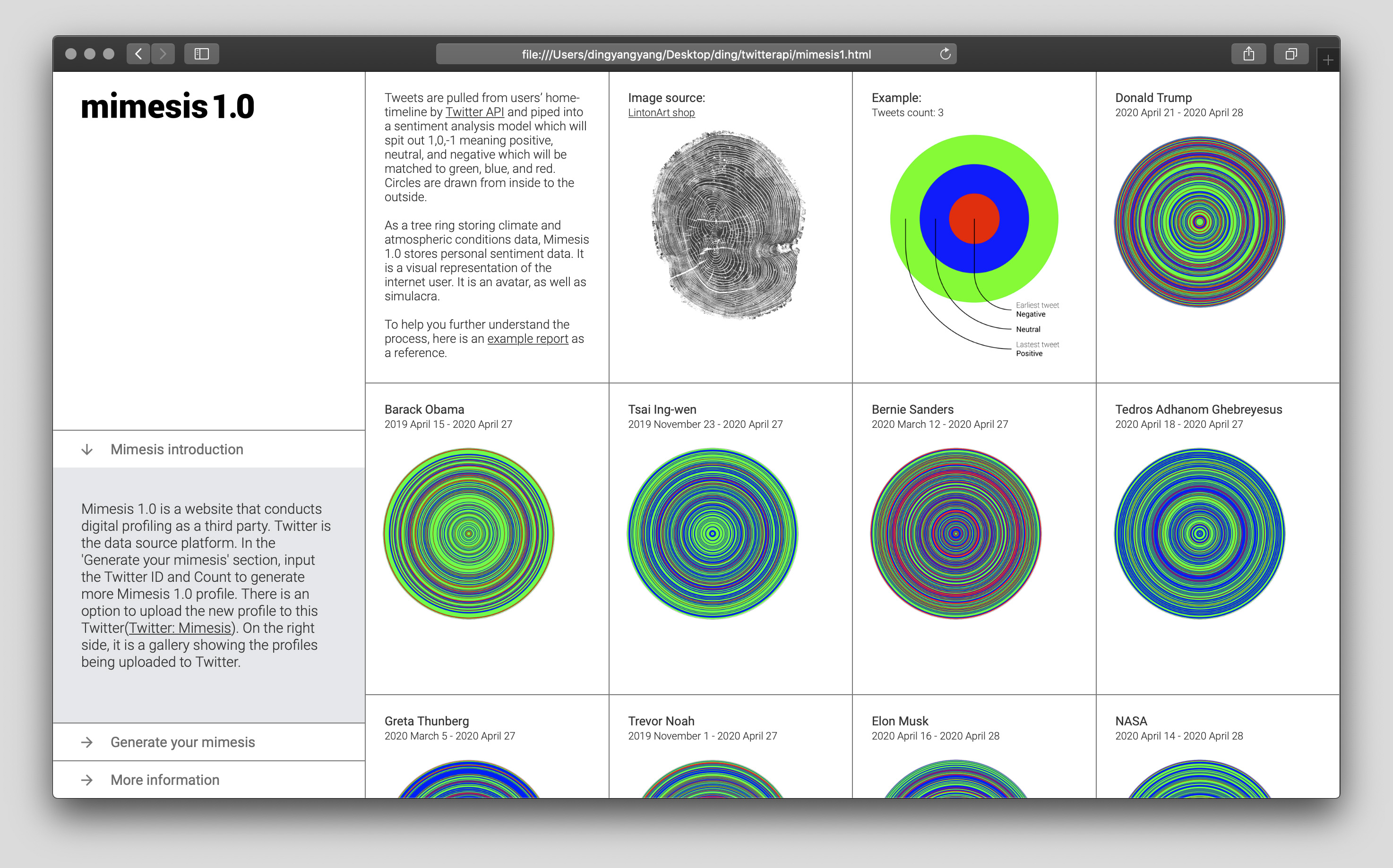
The goal of this website is to bring access to a broader range of audiences other than GitHub users. At the same time, it uses Mimesis as a medium to build a community that is also linked to a Twitter account.
The audience could input their information and submit their request in the 'view your Mimesis' section. Their Mimesis will be drawn and replace the placeholder. The new graph is also available for download. Their new requests will be updated in new blocks emerging after 'the latest request' block.
Special thanks to Benjamin Vu for helping composing javascript for this site.
mimesis2.0
Mimesis2.0 is the speculative result based on the same process as mimesis1.0, which is extracting data, conducting analysis, and drawing the result. The difference between 1.0 and 2.0 is not only replacing the sentiment model with the
cluster analysis mode
but also much higher complexity during the process. The MobileNet model in RunwayML(a democratized machine learning tool for artists and designers) is the one that I have used and tested for 2.0. Because this low fidelity model performs similar to the required cluster analysis model, which needs to be trained by enormous labeled datasets, the list of which will refer to the popular synsets in imagenet. After data is piped into the model, it generates several clusters. The names of these clusters are subsets of the labels in the data set, which will be
mapped to colors.
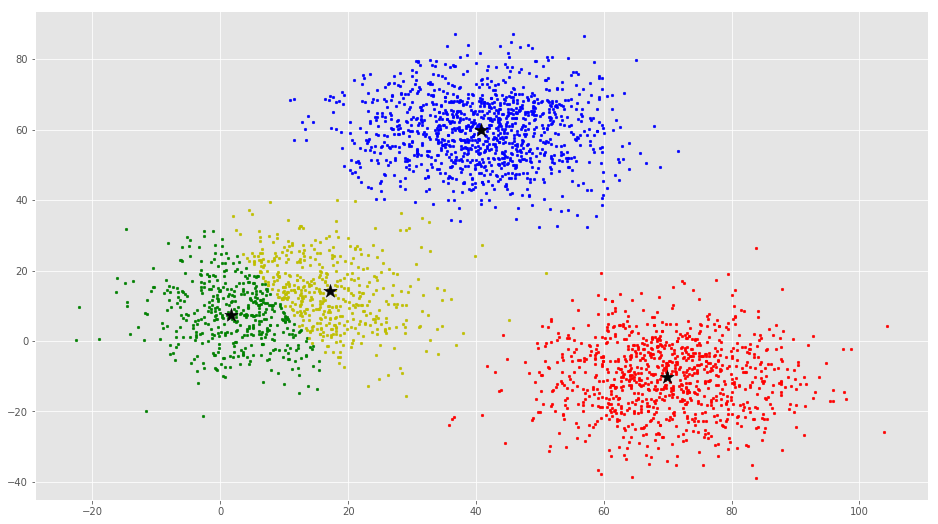
Cluster analysis model
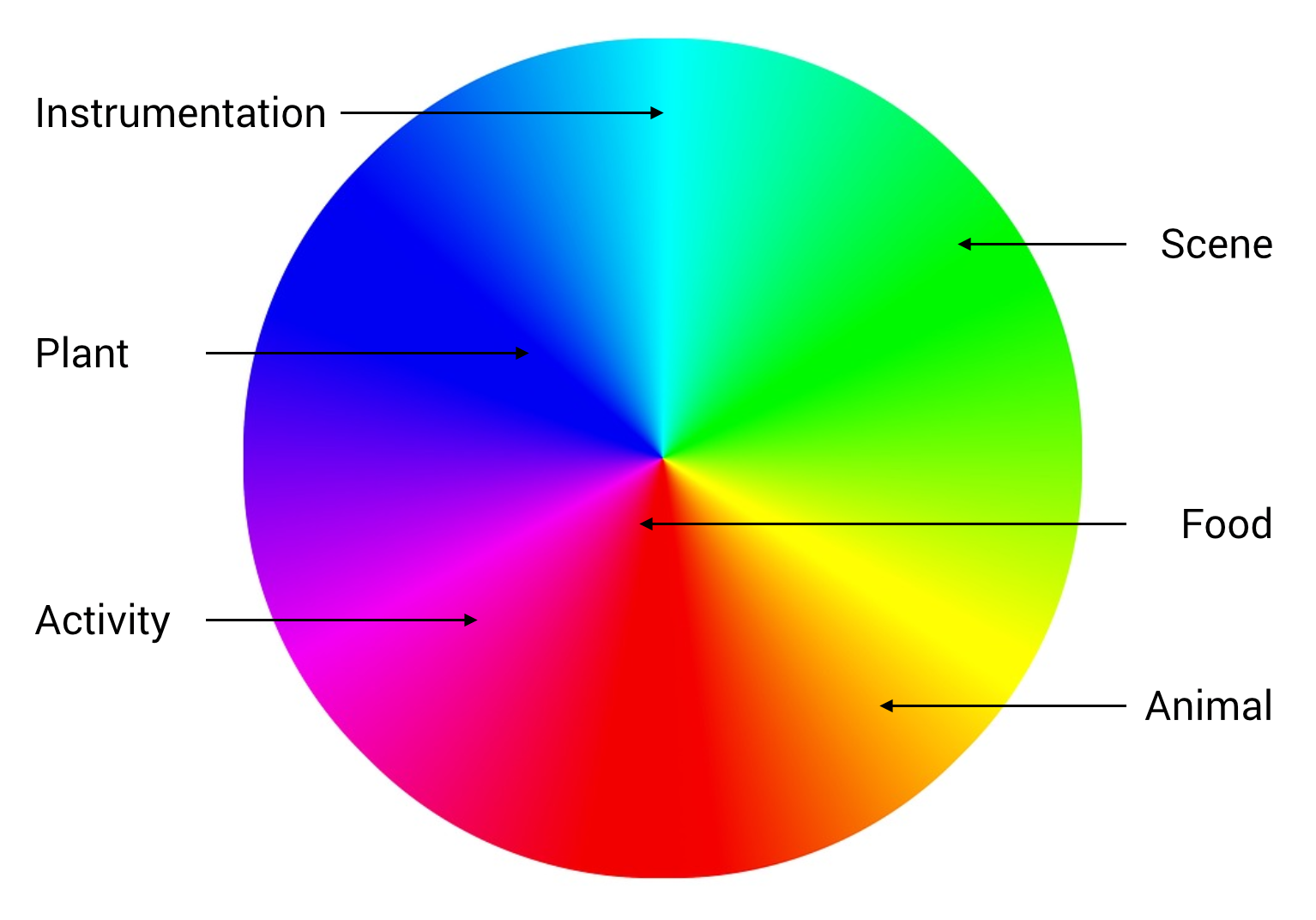
Color matching
Application scenarios
As mentioned before, the new ‘digital profiling’ visual identity will be hosted in the same context, which means corporates still hold control in hands. It is also a try-out by the third party, which is also a small win. The other potential application scenarios outlined below are one step further. It doesn’t mean these scenarios are against the context. It also doesn’t mean that there is no space for these scenarios to survive. The difference is how much control is given back to users. Projects like Nobias (Google extension), Alias (filter for Google Home), Gobo (social media filter) are great paradigms. These applications could be experiments, third party plugins, or actual products. Before carrying out applications, they need to be a proof of concept that could generate revenue through further experimentation, research, and policy development.
Each application consists of one visual outcome and one piece of description. The extrapolation is the extension of the past trajectory. The mediums vary from reports, to designs, to videos.
Personal Report
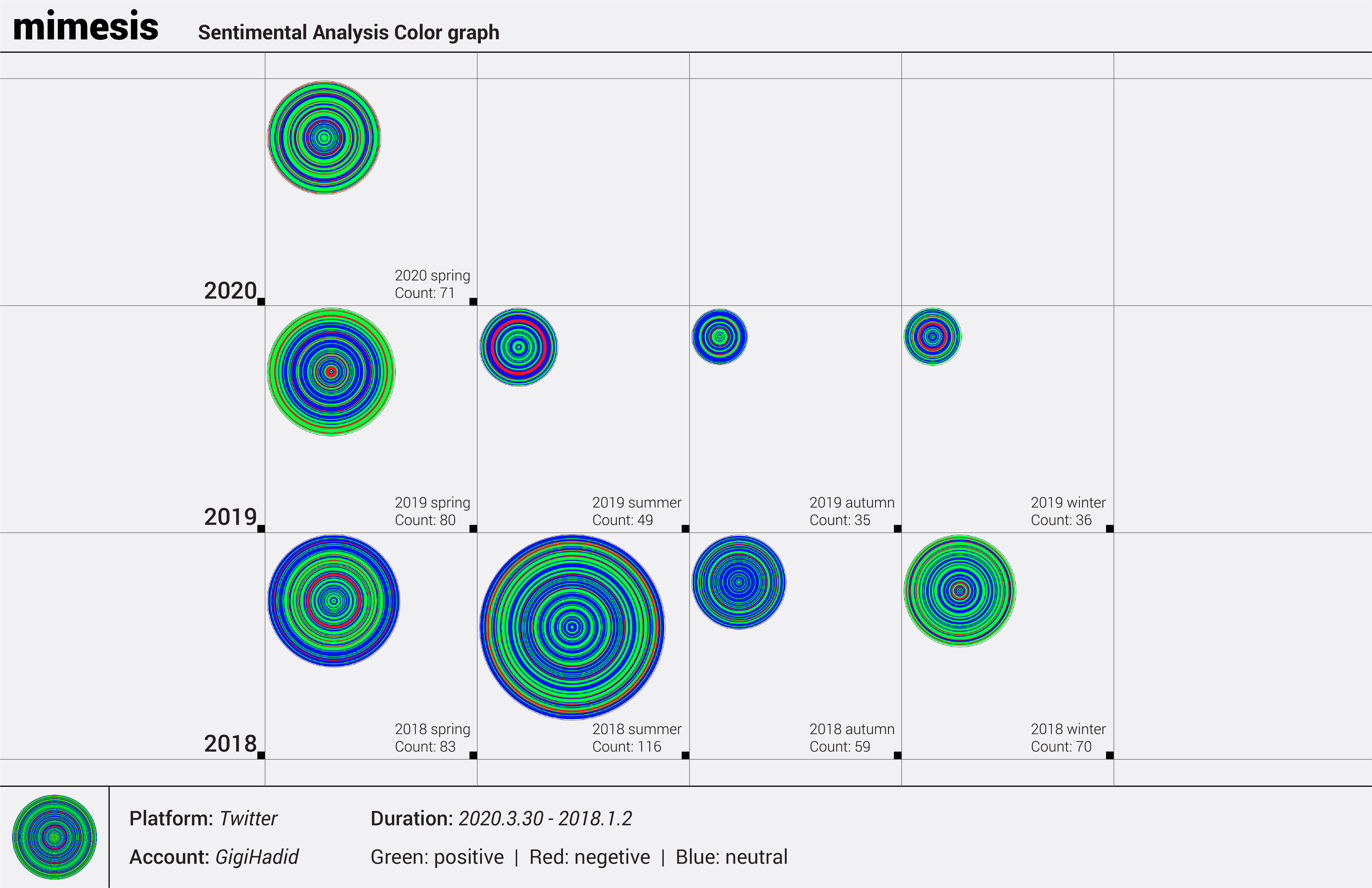
This personal report derives from the Mimesis1.0 functioning as further analysis of the Mimesis1.0 graph.
In RSPH's research report ‘Social Media and Young People's Mental Health and Wellbeing, five social media platforms, Youtube, Twitter, Facebook, Snapchat, and Instagram, are the primary targets in the survey, which is conducted among around 1,500 14 to 24-year-old people. Fourteen factors are being asked during the survey, including awareness, anxiety, loneliness, sleep, and self-expression. The result was Youtube ranked first and was the only positive platform among them all. Twitter ranked in 2nd place, then Facebook, Snapchat, and Instagram took last place.
At the same time, there is emerging research on the relationship between mental health and social media. 'We review recent work that utilizes social media "big data" in conjunction with associated technologies like natural language processing and machine learning to address pressing problems in population-level mental health surveillance and research, focusing both on technological advances and core ethical challenges.' Thus, this personal Twitter report might become auxiliary material for mental health analysis.
According to the trait of Twitter API and tweets object, there are two methods to filter tweets. The first method that twitter currently provides is seven parameters: name, count, since_id (from when), max_id (until when), trim_user, exclude_replies, and include_entities. When the request is submitted, these parameters help filter tweets. The second method is selecting the attributes in the tweet objects to write into a dictionary, and then filtering the dictionary for specific values of attributes. Filtering tweets according to different parameters might cater to different perspectives and needs.
Avatar for Tinder
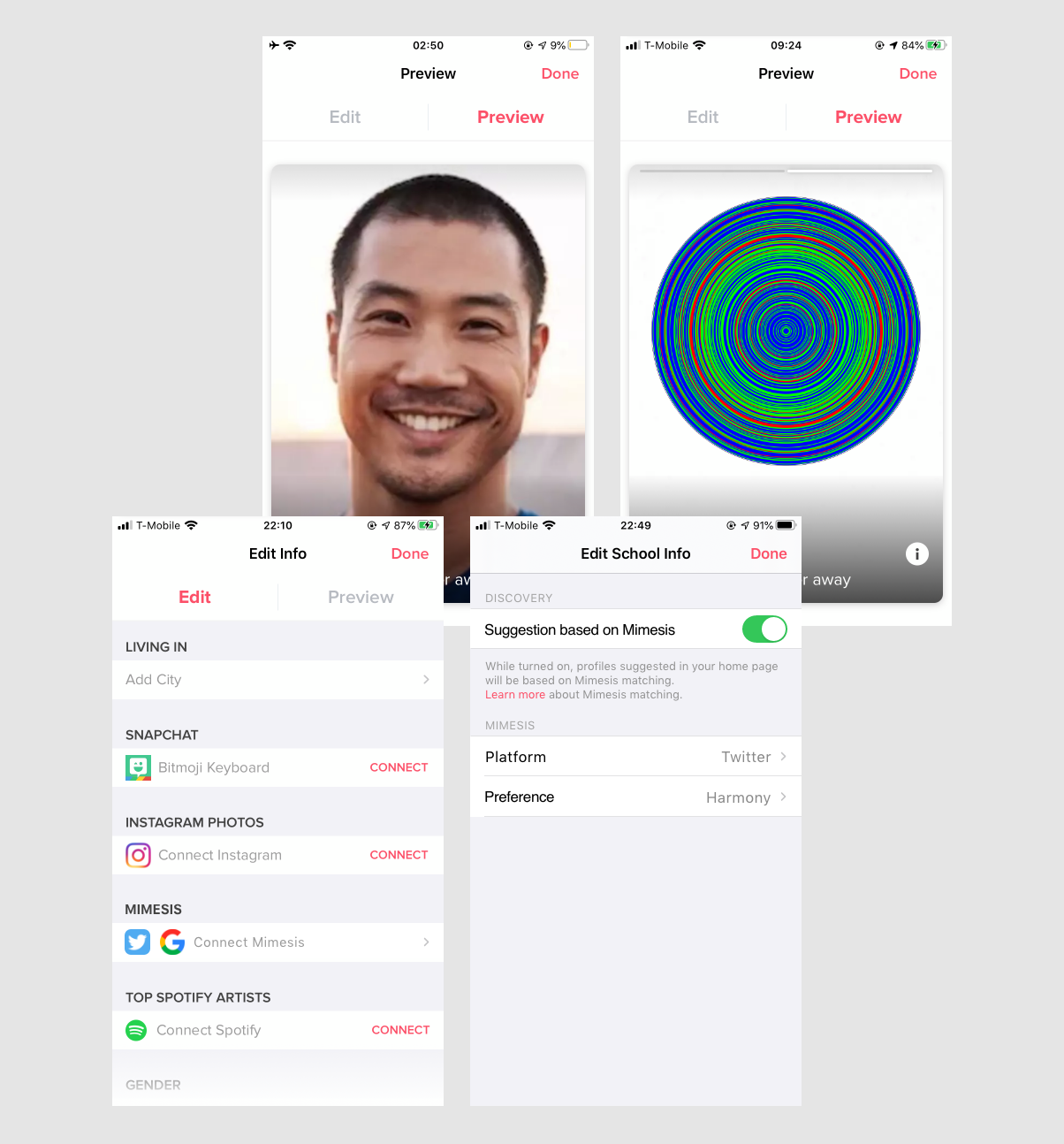
The media uses representations - images, words, and characters or persona - to convey ideas and values. On different social media platforms, we use different packages of information to display ourselves and interact with each other. There are also auxiliary tools like avatars creating applications to recreate an animation yourself. But still, the process of creating these avatars is an accumulation of socially and historically constructed concepts. In other words, gender, skin color, race, body shape, and face shape are still ingrained in those avatars. Prejudices are built into existing institutions and structures, and even though they look like a new medium, however, they still create barriers and limit opportunities.
Mimesis 1.0 is a customized graph, generated from the text by sentiment analysis, model, and processing. Although there is bias ingrained in constructing a deep learning model, results could be a new form of identity representation. Is it more natural and neutral? Does it break barriers and limits?
Tinder users can choose to connect Mimesis like Snapchat and Instagram photos. From a user's perspective, bridging Snapchat and Instagram with Tinder increases the plurality of information, though it might turn into a concern for some users. Mimesis shares the same idea offering Tinder users an option to show more about themselves. On top of that, Mimesis provides an alternative for matching algorithms. In color practice, there are multiple choices to collocate different colors. What if matching algorithms could use Mimesis as a source to incorporate color combination theory to expand users' options? Users' cards will be pushed to others based not only on age, distance, and gender preferences but also on their Mimesis matches.
Beauty filter for text editing

Platforms are places that will showcase your personality. There are a lot of behavior taxonomies out there. In Nancy White's research project: ‘Community Member Roles and Types,’ she came up with 15 archetype participation styles which are: core participants, readers/lurkers, dominators, linkers, flamers, actors, energy creatures, defenders, needlers, newbies, pollyAnnas, spammers, 'black & white' folks, 'shade of grey' folks and untouchable elders. Different archetypes maintain their style in multiple ways, including constructing a profile and engaging publicly in their own way.
In the book 'Virtual Social Identity and Consumer Behavior,' authors point out that the benchmark in adolescence is the kids’ desire and ability to explore multiple selves. It won't be a surprise that all internet users will not maintain the same identity through all the platforms. It's a fundamental desire to explore and embrace the other-selves within themselves. In everyday life, we approach every individual in a very different manner. Our behavior is based on the environment, who we are with, and what community we are in. This kind of behavior pattern can even be viewed on social platforms.
In Japanese, there is a phrase called '人設' (renshe) which originated from game design. It means the character design. Later on, in the Chinese internet environment, it became a phrase that is used to describe celebrities' public images. It is always designed by the company or celebrities' studio for marketing purposes. Gradually, every individual realized that they all have '人設' more or less. You might try to be tolerant, smart, or critical on Twitter. You might only post beautiful pictures on Instagram since it's visual-driven. The professional version of you will be on Linkedin.
There's a definite need here. What kind of application could help internet users build a better public image according to their needs? Currently, all different types of photo editing apps, beautifying filters, and avatar apps are prevailing. Most of these are visual-driven, targeting popular Instagram users. What’s next? What is the service for Twitter, and these text-driven platforms?
The Twitter bot has been published for almost a decade. The usage is still focused on research and some public services. 'The bot software may autonomously perform actions such as tweeting, re-tweeting, liking, following, unfollowing, or directly messaging other accounts. The automation of Twitter accounts is governed by a set of automation rules that outline proper and improper uses of automation.'
What if Mimesis is the automation rule that governs the bot? In that case, users could create certain types of Mimesis that follow specific behavioral patterns. In February, OpenAI published a language model called GPT-2 that generates coherent paragraphs of text one word at a time. Mimesis, GPT-2 model, and Twitter bot complete the critical components in the new application for Twitter.
Feedback loop
Thomas Goetz mentioned that a feedback loop involves four distinct stages: evidence, relevance, consequence, and operation.From the user experience design perspective, it is not complicated to build a real feedback loop to counterbalance the dopamine-driven 'feedback loop.' It is possible to imagine a feedback loop where there is relevant evidence that can trigger users to adjust their subsequent behavioral. In the article ‘Harnessing the Power of Feedback Loop’, there is a case that city engineers slow down drivers in school zones by an average of 14 percent by merely showing current speed to the drivers on a dynamic speed display.
For Mimesis 2.0 and the ideal Mimesis, the speculative application happens on platforms functioning as user's information resources. In this scenario, the demonstration executes on Instagram's home page, which will be used as the background of the app. There are two different stages of the Mimesis. In the first stage, colors won't change but rather they’ll slowly float. The second stage will be triggered by the posts that are liked by the user. The new liked post will be analyzed by the system, and the analysis outcome will decide to increase, decrease or change colors. Referring back to the four stages of the feedback loop: evidence, relevance, consequence, and operation, Mimesis embedded in the background functions as the relevant evidence of the user's liked posts. When users’ likes are limited to a few categories of posts, the diversity of colors in Mimesis will diminish. This builds the consequence stage, which informs users of their 'bubble.' And finally, the 'bubble' nudges users to operate and completes the feedback loop.
What's more, this is not a speculation of what comes after dark mode design, but it could be an alternative option. Dark mode design has been criticized for not being proven to improve focus or productivity. A new design feature is a better definition of what it is. Mimesis background is designed as a feedback loop, as well as a customized background (for marketing).
Content moderator
The content moderator is the reverse engineering of the ideal mimesis. In this system, you have two slide bars to control your feeds. The variety of themes is linked to the diversity of the colors, and variety of perspectives is linked to the saturation of the colors.
The close future of digital profiling
The goal of this essay is to explore three main issues (from the users’ side; lack of transparency in data collecting and processing, lack of control, and lack of feedback loop for confirmation bias.) inside digital profiling, followed by my solution to these issues and the applications. My stance toward this topic is neither against the powerful internet platforms nor to introduce some technology that will block data collection - it is to imagine possible futures where digital profiling could become human-centered instead of advertising-driven.
The spiral and the loop
As Julia Cameron puts it in The Artist’s Way, "You will circle through some of the issues over and over, each time at a different level. There is no such thing as being done with an artistic life. Frustrations and rewards exist at all levels on the path. Our aim here is to find the trail, establish our footing, and begin the climb.""
This essay dives deeper into the research of the system. It shows a more transparent and detailed picture of the digital profiling system. My aim here is to ‘find the trail, establish our footing, and begin the climb.’ In other words, this essay paves the path toward my stance on why we need a more human-centered digital profiling system.
Three research maps